Gemini 1.5 Pro คือ Chat Bot AI รุ่นล่าสุดของทาง Google ที่เป็นหนึ่งใน AI Chat ที่มาแรงเป็นอย่างมาก แน่นอนว่าการเข้าถึงมันนั้นต้องเสียเงิน มาดู ฟีเจอร์ที่ถ้าคุณต้องเสียเงินแล้วจะได้มันกัน

Gemini 1.5 เปิดตัวมาได้สักพักและมาพร้อมกับตัวอย่างสำหรับ Gemini 1.5 Pro โดย Gemini Pro เป็นรุ่นที่ขับเคลื่อน Gemini เวอร์ชันฟรี ซึ่งหมายความว่าผู้บริโภคทั่วไปจะได้ใช้งานฟรีเร็วๆ นี้ หากคุณตื่นเต้นกับมัน เรามีรายการทุกสิ่งที่ Google บอกว่า Gemini 1.5 Pro ทำได้ แต่ Gemini 1.0 ทำไม่ได้มาให้คุณได้ศึกษากัน
- Gemini 1.5 มีหน้าต่างบริบทที่ใหญ่กว่ามาก
- Gemini 1.5 Pro สามารถเขียนโค้ดได้ดีกว่ามาก
- สามารถวิเคราะห์ข้อมูลจำนวนมากได้
- สามารถเรียนรู้ได้ในการสนทนา
- มันตอบสนองเร็วขึ้น
Gemini 1.5 มีหน้าต่างบริบทที่ใหญ่กว่ามาก
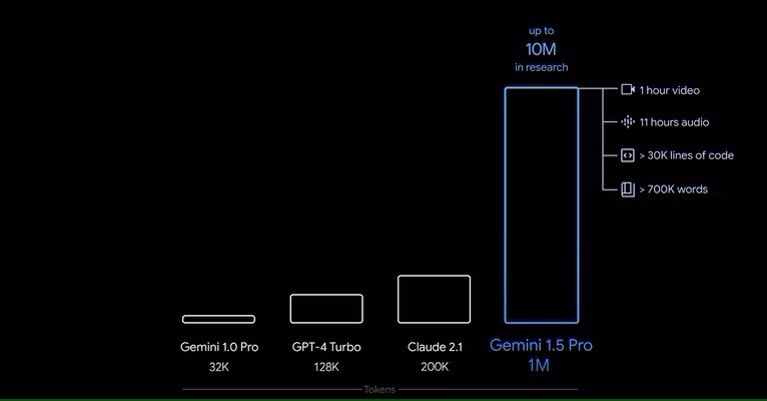
Gemini 1.5 มีหน้าต่างบริบทที่สามารถรับโทเค็นได้มากถึง 10 ล้านโทเค็นในการวิจัยและจะมีโทเค็นมากถึง 1 ล้านโทเค็นสำหรับผู้บริโภคทั่วไป หน้าต่างบริบทที่ใหญ่ขึ้นนั้นจะต้องเสียค่าใช้จ่าย แต่ Gemini 1.5 Pro เวอร์ชันฟรีจะยังคงมาพร้อมกับหน้าต่างบริบทขนาด 128K สำหรับการอ้างอิง GPT-4 Turbo มีหน้าต่างบริบท 128K เช่นกัน และทั้ง Gemini Pro ในขณะนี้และ GPT-4 ปกติก็มีหน้าต่างบริบท 32K 1 ล้านโทเค็นถือเป็นครั้งแรกในอุตสาหกรรม
หน้าต่างบริบทในปัญญาประดิษฐ์ทำหน้าที่เป็นหน่วยความจำรวมที่มีอิทธิพลต่อการประมวลผลของ AI โดยสรุปอินพุตทั้งหมดที่จำเป็นสำหรับ AI เพื่อทำความเข้าใจคำถามและกำหนดคำตอบ ซึ่งรวมถึงข้อความแจ้งเริ่มต้นจากผู้ใช้ พร้อมด้วยบริบทเสริมหรือการโต้ตอบก่อนหน้า ความกว้างของหน้าต่างบริบทมีบทบาทสำคัญในการกำหนดปริมาณข้อมูลที่โมเดลสามารถเก็บไว้จากส่วนก่อนหน้าของการสนทนาหรือข้อความ ซึ่งส่งผลโดยตรงต่อความสามารถในการส่งมอบการตอบสนองที่สอดคล้องกันและตรงประเด็น
ผู้ใช้จะได้รับประโยชน์มากน้อยเพียงใดนั้นขึ้นอยู่กับวิธีที่พวกเขาใช้ LLM หากคุณเพียงต้องการถามคำถามพื้นฐานและไม่ทำอะไรมาก คุณจะไม่ได้รับประโยชน์จริงๆ หากคุณใช้ LLM ในการเขียนโค้ดหรือสิ่งอื่นๆ ที่อาจมีการตอบสนองนานกว่า หน้าต่างบริบทที่ใหญ่ขึ้นจะเป็นประโยชน์ต่อคุณจริงๆ Google บอกว่าคาดหวังเวลาแฝงที่สูงขึ้นในหน้าต่างบริบทที่สูงขึ้น แต่คาดว่าจะเกิดขึ้นในปัจจุบัน
Gemini 1.5 Pro สามารถเขียนโค้ดได้ดีกว่ามาก
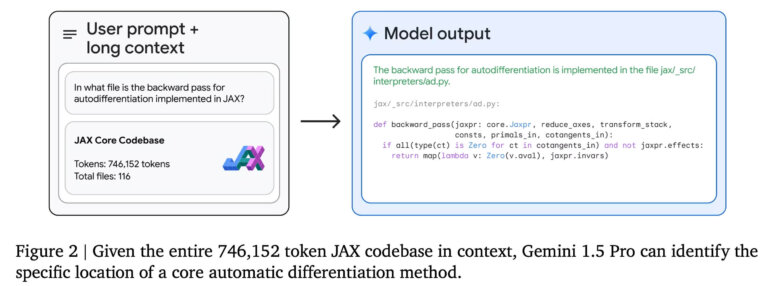
หากคุณใช้ LLM ในการเขียนโค้ด คุณจะดีใจที่รู้ว่า Gemini 1.5 Pro ทำงานได้ดีกว่าในการเขียนโค้ดมากกว่า Gemini 1.0 Ultra นับประสาอะไรกับ Gemini 1.5 Pro นั่นเป็นไปตามเอกสารทางเทคนิคของ Google ซึ่งระบุไว้ดังต่อไปนี้
Gemini 1.5 Pro เป็นโมเดลโค้ดที่มีประสิทธิภาพดีที่สุดของเราจนถึงปัจจุบัน ซึ่งเหนือกว่า Gemini 1.0 Ultra ใน Natural2Code ซึ่งเป็นชุดทดสอบการสร้างโค้ดแบบระงับภายในของเราที่สร้างขึ้นเพื่อป้องกันการรั่วไหลของเว็บ
สำหรับใครก็ตามที่ใช้ LLM ในการเขียนโค้ด นี่ถือเป็นเรื่องใหญ่ Gemini Advanced เก่งด้านการเขียนโปรแกรม แต่ก็สามารถยืนหยัดเพื่อให้ดีกว่านี้ได้เสมอและเรายังคงชอบ ChatGPT Plus สำหรับทุกสิ่งที่เกี่ยวข้องกับการเขียนโปรแกรมที่เราทำ ถ้ามันเขียนโปรแกรมได้ดีกว่ารุ่น Ultra แสดงว่าเป็นลางดีจริงๆ สำหรับทุกคนที่ใช้มันเพื่อเขียนโปรแกรมตามปกติ
สามารถวิเคราะห์ข้อมูลจำนวนมากได้
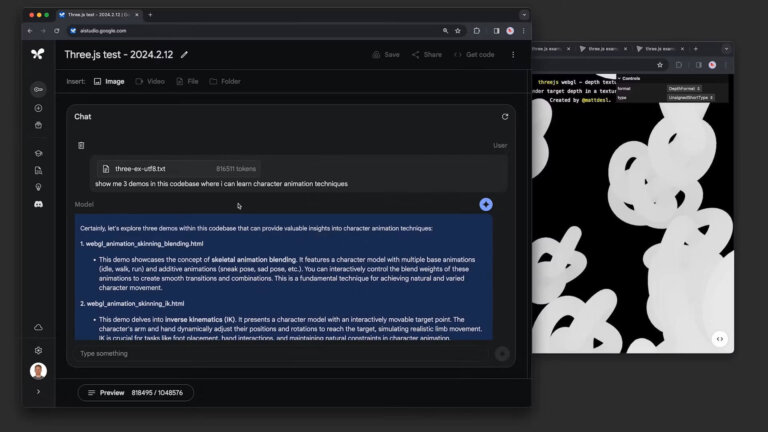
เนื่องจากเป็นผลพลอยได้จากหน้าต่างบริบทที่ใหญ่ขึ้น Gemini 1.5 Pro จึงสามารถเข้าใจสิ่งที่คุณให้ได้มากขึ้น แม้ว่าสิ่งนี้จะถือว่าเกิดขึ้นเนื่องจากหน้าต่างบริบทเพิ่มขึ้น แต่ก็ไม่มีการรับประกันว่า LLM จะสามารถตอบสนองด้วยคุณภาพในระดับเดียวกันกับอินพุตที่ใหญ่กว่าได้เหมือนกับที่สามารถตอบสนองด้วยอินพุตที่เล็กกว่าได้ Google ให้ความมั่นใจกับผู้คนว่าสามารถตอบสนองอินพุตที่ใหญ่กว่าได้พอๆ กับอินพุตที่สั้นกว่า โดยสาธิตโดยการขอความช่วยเหลือจาก Gemini เกี่ยวกับโปรแกรมที่มีโค้ดมากกว่า 100,000 บรรทัด
ด้วยเหตุนี้ Google จึงกล่าวว่าสามารถให้การแก้ไข, ข้อเสนอแนะและช่วยเหลืออินพุตจำนวนมากในคราวเดียวได้อย่างสมเหตุสมผล โดยโค้ดเบสข้างต้นใช้โทเค็นมากกว่า 800,000 รายการ นั่นเป็นจำนวนโทเค็นที่มากจนเกือบไร้สาระและมากกว่า LLM อื่นๆ ที่สามารถทำได้ในปัจจุบัน ด้วยเหตุนี้ Google จึงให้หนังเงียบความยาว 44 นาที โดยถาม AI เกี่ยวกับรายละเอียดเฉพาะในภาพยนตร์ ก็สามารถตอบสนองด้วยคำตอบที่ถูกต้อง
Gemini 1.5 Pro ขยายขอบเขตความยาวบริบทนี้ไปสู่โทเค็นหลายล้านรายการอย่างมีนัยสำคัญ โดยแทบไม่มีการลดทอนประสิทธิภาพเลย ทำให้สามารถประมวลผลอินพุตที่ใหญ่ขึ้นอย่างเห็นได้ชัด เมื่อเปรียบเทียบกับ Claude 2.1 ที่มีหน้าต่างบริบทโทเค็น 200,000 Gemini 1.5 Pro สามารถเรียกคืนได้ 100% ด้วยโทเค็น 200,000 โทเค็น ซึ่งเหนือกว่า Claude 2.1 ที่ 98% การเรียกคืน 100% นี้รักษาไว้ได้ถึง 530,000 โทเค็น และการเรียกคืนคือ 99.7% ที่ 1M โทเค็น เมื่อเพิ่มจาก 1M โทเค็นเป็น 10M โทเค็น โมเดลยังคงสามารถเรียกคืนได้ 99.2%
นอกจากนี้ Google ยังจัดเตรียมสำเนา 402 หน้าทั้งหมดของการควบคุมภาคพื้นดินสู่อากาศด้วย Apollo 11 อีกด้วย และก็สามารถทำเช่นเดียวกันได้เช่นกัน ความสามารถในการแยกวิเคราะห์ข้อมูลจำนวนมากถือเป็นข้อดีที่สำคัญของ Google และจะช่วยผู้ที่จัดการฐานโค้ดขนาดใหญ่หรือสืบค้นข้อมูลจำนวนมาก
Google อธิบายวิธีการใช้การประเมินแบบ Needle In A Haystack โดยที่ข้อความชิ้นเล็กๆ ที่มีข้อเท็จจริงหรือข้อความเฉพาะเจาะจงถูกซ่อนไว้ภายในบล็อกข้อความยาวๆ Gemini 1.5 Pro พบว่าใช้งานได้ 99% แม้จะอยู่ในกลุ่มข้อมูลที่เต็มหน้าต่างบริบท 1 ล้านรายการก็ตาม
สามารถเรียนรู้ได้ในการสนทนา
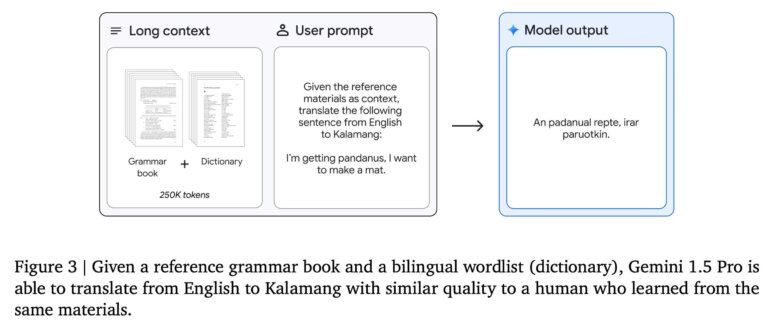
LLM ไม่สามารถทำทุกอย่างได้ โดยเฉพาะอย่างยิ่งหากไม่ได้รับการฝึกอบรมเกี่ยวกับข้อมูลที่ดูเหมือนว่าจะเป็นคำตอบสำหรับข้อความแจ้ง นั่นเป็นเหตุผลว่าทำไม LLM จึงไม่มีประสิทธิภาพมากนักสำหรับภาษาเล็กๆ คุณสามารถลองสอนภาษา LLM ได้ แต่มีโอกาสที่คุณจะกรอกหน้าต่างบริบทไม่เช่นนั้นภาษาจะไม่สามารถปรับตัวได้ นักวิจัยที่ Google สอน Gemini 1.5 Pro Kalamang ด้วยการมอบคู่มือไวยากรณ์ ซึ่งเป็นภาษาที่มีผู้พูดน้อยกว่า 200 คนทั่วโลก พวกเขากล่าวว่าโมเดลนี้สามารถ “แปลภาษาอังกฤษเป็นภาษาคาลามังได้ในระดับใกล้เคียงกับบุคคลที่เรียนรู้จากเนื้อหาเดียวกัน”
แม้ว่าจะไม่สมบูรณ์แบบ แต่ก็หมายความว่า LLM ของ Google จะสามารถรับข้อมูลเพิ่มเติมที่คุณให้มาซึ่งอาจไม่เคยรู้มาก่อนและนำไปใช้กับส่วนที่เหลือของการสนทนา
มันตอบสนองเร็วขึ้น
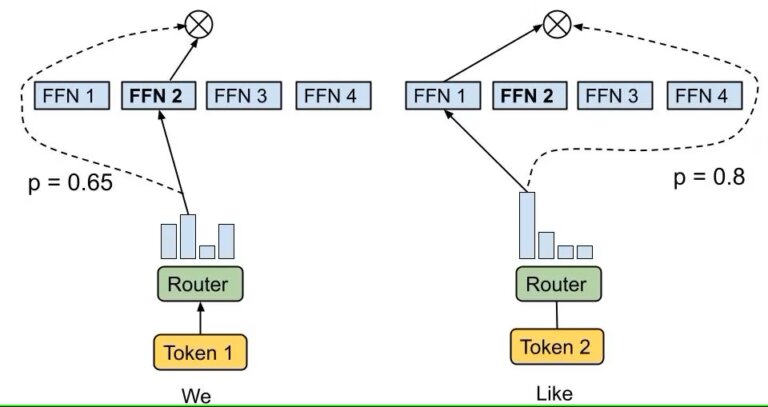
LLM ที่รวมเอาอินพุตกระบวนการสถาปัตยกรรม Mixture-of-Experts (MoE) ไว้ด้วยการกำหนดเส้นทางโทเค็นไปยังโครงข่ายประสาทเทียมเฉพาะภายในระบบ ซึ่งได้รับการเลือกให้มีความเกี่ยวข้องกับงานที่มีอยู่ สถาปัตยกรรมนี้ช่วยให้สามารถตอบคำถามได้อย่างไดนามิกและมีประสิทธิภาพ โดยมีศักยภาพในการจัดโครงสร้างแบบลำดับชั้นโดยที่เครือข่ายผู้เชี่ยวชาญอาจเป็น MoE กระบวนการคัดเลือกเกี่ยวข้องกับเครือข่ายการกำหนดเส้นทางที่ระบุผู้เชี่ยวชาญที่เหมาะสมที่สุดสำหรับแต่ละโทเค็น ส่งผลให้เกิดการตอบสนองที่เกิดจากความเชี่ยวชาญที่ผสมผสานกันของโครงข่ายประสาทเทียมหลายเครือข่าย ขณะนี้ Gemini ใช้สถาปัตยกรรม MoE ซึ่งน่าจะส่งผลให้ได้รับคำตอบเร็วขึ้น
สถาปัตยกรรม MoE ช่วยเพิ่มประสิทธิภาพในการคำนวณ โดยเฉพาะอย่างยิ่งในระหว่างระยะการฝึกเริ่มต้นของโมเดล แม้ว่าอาจนำไปสู่การติดตั้งมากเกินไประหว่างการปรับแต่งแบบละเอียด ซึ่งโมเดลจะจดจำและจำลองข้อมูลการฝึกมากเกินไป นอกจากนี้ MoE ยังสามารถเสนอเวลาการอนุมานที่รวดเร็วยิ่งขึ้นด้วยการเปิดใช้งานเฉพาะกลุ่มผู้เชี่ยวชาญที่เกี่ยวข้องสำหรับการสืบค้นแต่ละครั้ง ซึ่งจะช่วยเพิ่มประสิทธิภาพการใช้ทรัพยากร อย่างไรก็ตาม การสนับสนุนโมเดลที่ซับซ้อนดังกล่าวจำเป็นต้องใช้ทรัพยากรหน่วยความจำจำนวนมาก เนื่องจากพารามิเตอร์จำนวนมาก ซึ่งมักจะเป็นพันล้าน ต้องใช้ RAM จำนวนมากเพื่อการทำงานที่มีประสิทธิภาพ
แม้ว่าจะไม่ชัดเจนว่าสิ่งนี้จะเป็นประโยชน์ต่อ Gemini อย่างไร แต่ก็ควรจะสามารถอนุมานได้เร็วกว่ารุ่นก่อนมาก Mixtral 8x7B เป็นหนึ่งใน LLM ที่รวม MoE เข้าด้วยกันจนประสบความสำเร็จอย่างมาก โดยสร้างโมเดลที่มีพลังเท่ากับรุ่น 47B ในขณะที่ต้องการเพียงความสามารถที่จำเป็นในการรันโมเดล 12.9B เท่านั้น มีข้อดีมากมายทั้งในด้านประสิทธิภาพและการประหยัดต้นทุนสำหรับ Google ซึ่งเป็นสาเหตุที่เราสงสัยว่าพวกเขากำลังใช้งานอยู่
Gemini 1.5 ถือเป็นก้าวสำคัญของ Google
การปรับปรุงที่ใหญ่ที่สุดที่นี่คือหน้าต่างบริบทที่ใหญ่ขึ้นอย่างไม่ต้องสงสัย เนื่องจากช่วยให้สามารถปรับปรุงได้มากมาย Google ยังกล่าวอีกว่า Gemini 1.5 Pro มีประสิทธิภาพเหนือกว่า Gemini 1.0 Ultra ในสถานการณ์ต่างๆ มากมาย “แม้ว่า Gemini 1.5 Pro จะใช้การประมวลผลการฝึกอบรมน้อยกว่าอย่างเห็นได้ชัดและมีประสิทธิภาพในการให้บริการมากกว่า” มีเรื่องให้ตื่นเต้นมากมายที่นี่ โดยเฉพาะอย่างยิ่งหากคุณเป็นผู้ใช้งาน LLM หรือผู้ที่ตื่นเต้นกับการพัฒนา AI โดยทั่วไป
การเปลี่ยนแปลงเหล่านี้จะเกิดขึ้นกับผู้บริโภคเมื่อใดยังไม่ชัดเจนนัก เนื่องจากนักพัฒนาสามารถเริ่มใช้ Gemini 1.5 Pro ได้แล้ววันนี้ Gemini 1.5 Ultra คาดว่าจะอยู่ในขั้นตอนการผลิตเช่นกัน แม้ว่า Google จะยังไม่ได้กล่าวถึงอะไรก็ตาม ถึงกระนั้น ก็เป็นที่ชัดเจนว่า Google ต้องการเป็นผู้เล่น AI ที่ดีที่สุดในโลก
ที่มา : xda